NVIDIA Omniverse is key to bringing advanced architectural design concepts combining AI, simulation and collaborative workflows to the next generation of students.
NVIDIA Omniverse is key to bringing advanced architectural design concepts combining AI, simulation and collaborative workflows to the next generation of students.
NVIDIA announced at SIGGRAPH several additions to its Deep Learning Institute (DLI) curriculum, including an introductory course to Pixar’s Universal Scene Description (USD) and a teaching kit for educators, looking to incorporate hands-on technical training into graphics, architectural design, and digital media production coursework.
The teaching kit will be based on NVIDIA Omniverse, an open platform for virtual collaboration and real-time simulation for quick and easy creation of photorealistic, physically accurate designs.
NVIDIA is collaborating with Professor Don Greenberg from Cornell University
NVIDIA Omniverse is key to bringing advanced architectural design concepts—which combine AI, simulation, and collaborative workflows—to the next generation of students.
Professor Don Greenberg will be joining NVIDIA to codevelop Omniverse-based lecture materials, hands-on exercises, and strategies for early-stage design, which can be integrated into class curricula. Greenberg is Cornell University’s Jacob Gould Schurman Professor of Computer Graphics in the College of Architecture, Art, and Planning’s Department of Architecture and Director of the Cornell Program of Computer Graphics.
Greenberg’s expertise is extensive, having authored hundreds of articles, and educated thousands of computer graphics students, architects, and structural engineers. A Coon’s awards winner in 1987, two of his students (Rob Cook and Michael Cohen) have also won the award. Among Greenberg’s students, six have won the SIGGRAPH Achievement Award, and 16 have won Academy Awards for Scientific and Technical Achievements.
“Omniverse, combined with the computational power of new NVIDIA graphics boards, holds the incredible potential to improve early design strategies. This is the time in the design cycle when the most important design decisions are made. By combining the sketched ideas with rapid feedback from parametric studies, such as energy performance, structural Integrity, life cycle costing, or the overall appearance or view options from the nonexistent simulated building in context, better and more comprehensive solutions can be obtained from sketch to reality,” said Greenberg. “I am really excited to start this collaboration with NVIDIA and make these next generation design tools available to other schools and the profession.”
New DLI Graphics and Omniverse Teaching Kit
Designed for educators, the new Graphics & Omniverse Teaching Kit is being developed in consultation with top digital media, film, game development, animation, and visual effects schools as part of the NVIDIA Studio Education Partner Program.
Comprehensive and modular, the kit will include lecture materials, quiz problem sets, hands-on exercises, NVIDIA GPU Cloud resources, and more. It is ideal for college and university educators looking to bring graphics and NVIDIA Omniverse into their classrooms, enabling the next generation of creatives. Students will have the opportunity to receive certificates of competency to support career growth.
The kit will also incorporate teaching materials from The Graphics Codex, an in-depth computer rendering resource covering ray tracing, materials, GPU programming, and human perception. The Graphics Codex was written by Morgan McGuire, the Chief Scientist at Roblox and Computer Science professor at the Universe of Waterloo and McGill University. Also included is the new Ray Tracing Gems II ebook, authored by Adam Marrs, which covers Next Generation Real-Time Rendering with DXR, Vulkan, and OptiX. Marrs is a senior graphics engineer in the Game Engines and Core Technology group at NVIDIA, where he works on real-time rendering for games and film.
More content is being added and early access applications for educators are now available.
New DLI Training for Everyone
For those wanting to start using Omniverse to create their own masterpieces but not sure where to start, NVIDIA launched a new DLI training course called Getting Started with Universal Scene Description for Collaborative 3D Workflows.
This self-paced, introductory training course familiarizes users with Universal Scene Description (USD), a framework created by Pixar for the interchange of 3D computer graphics data. USD focuses on collaboration, nondestructive editing, and multiple views and opinions on graphics data.
The course covers the history and purpose of USD, an overview of scene composition using Python, and includes a series of hands-on exercises consisting of training videos and live scripted examples. Developers will master important concepts such as layer composition, references, and variants.
This course can be taken anytime, anywhere, with just a computer and an Internet connection—enroll here.
Also released at SIGGRAPH is Masterclass by the Masters – Using Omniverse for Artistic 3D Workflows, a new video series focused on how Omniverse can be customized for artistic and creative workflows. Viewers will experience a collection of vignettes made by experts and creative masters, plus live-edit, multi-app workflows using Omniverse Connectors, as well as scene composition and rendering in Omniverse Create.
DLI’s top-rated Fundamentals of Deep Learning will be available at a special offer to all SIGGRAPH attendees throughout August and September. Use the code DLI_SIGGRAPH21 to receive 25% off this workshop. This instructor-led course takes participants through the workings of deep learning with hands-on exercises in computer vision and natural language processing. Those who complete the course will earn a certificate demonstrating their subject matter competency and supporting career growth.
These courses are just a fraction of what is offered through NVIDIA DLI. Since 2017, DLI has trained more than 300,000 developers through an extensive catalog of training offerings.
For other NVIDIA announcements and events at this year’s SIGGRAPH, including even more training opportunities, visit the SIGGRAPH page.

 NVIDIA researchers are presenting five papers on our groundbreaking research in speech recognition and synthesis at INTERSPEECH 2021.
NVIDIA researchers are presenting five papers on our groundbreaking research in speech recognition and synthesis at INTERSPEECH 2021. 

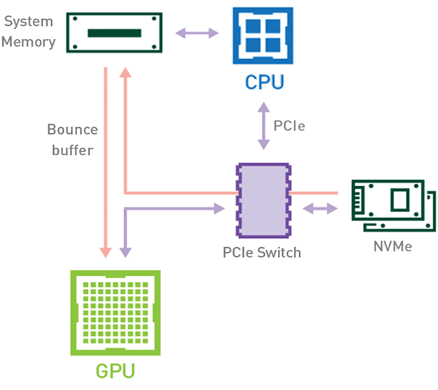
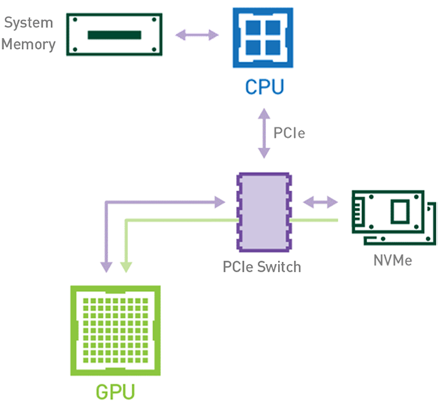
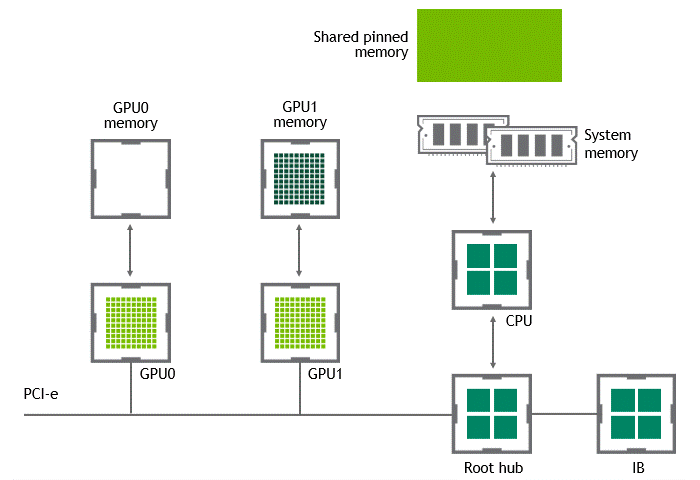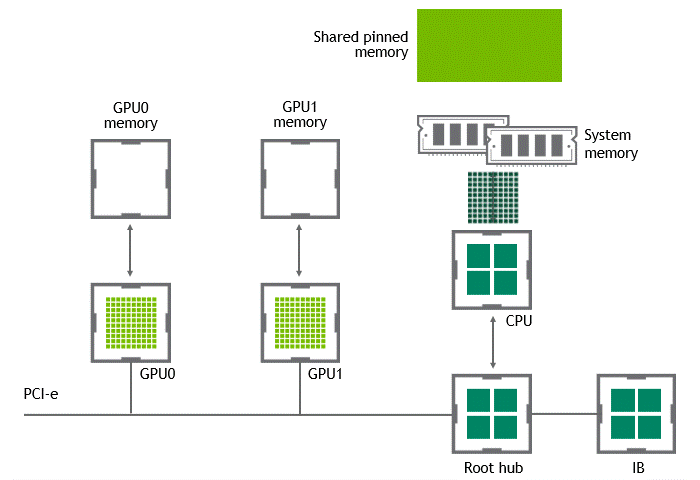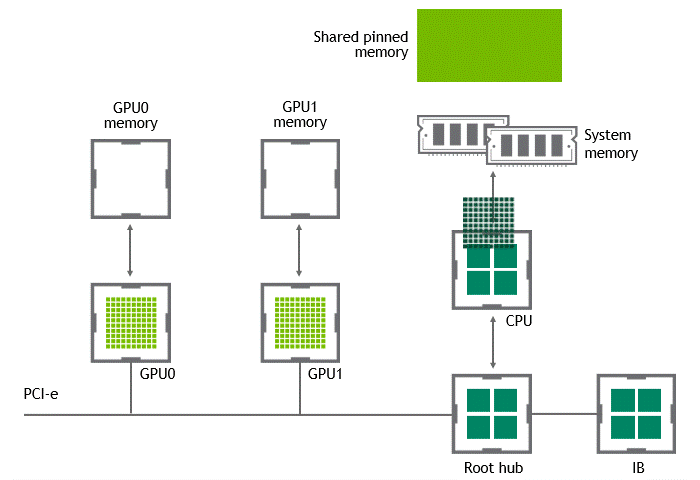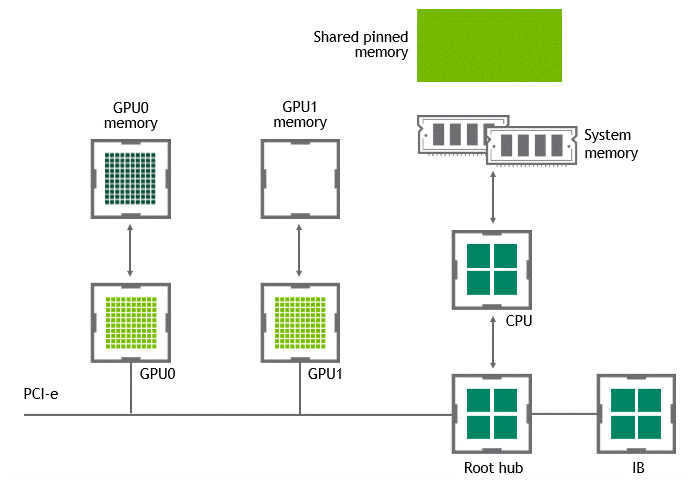
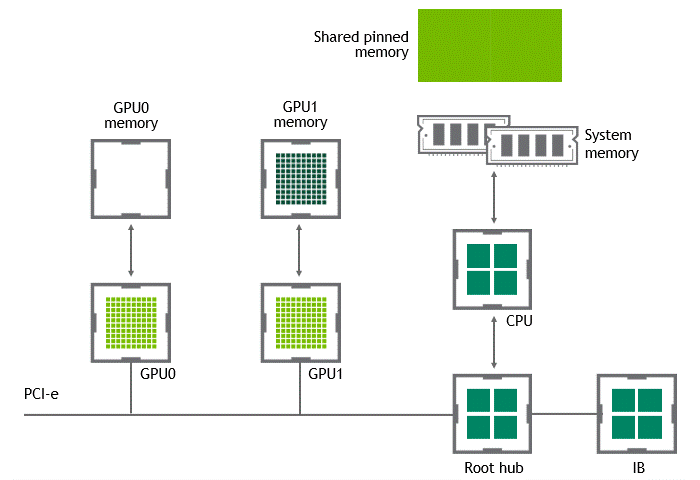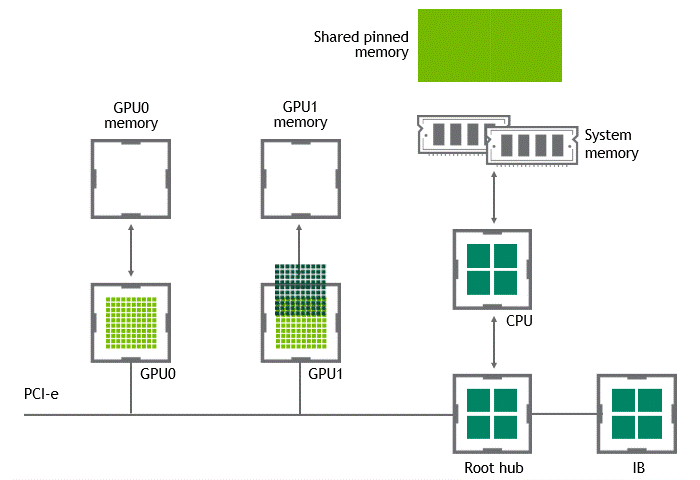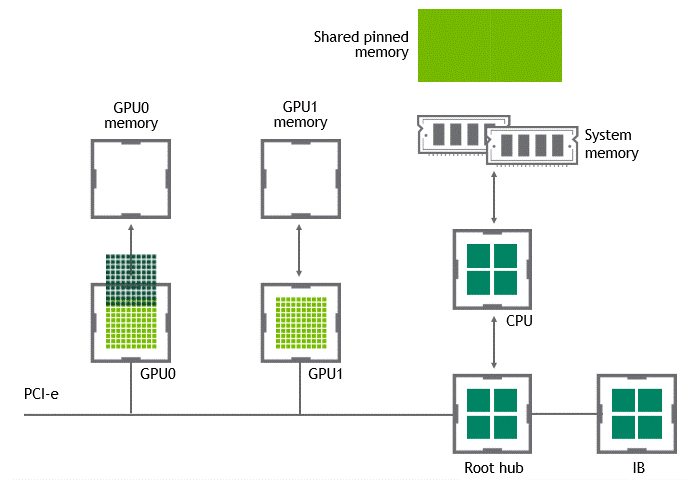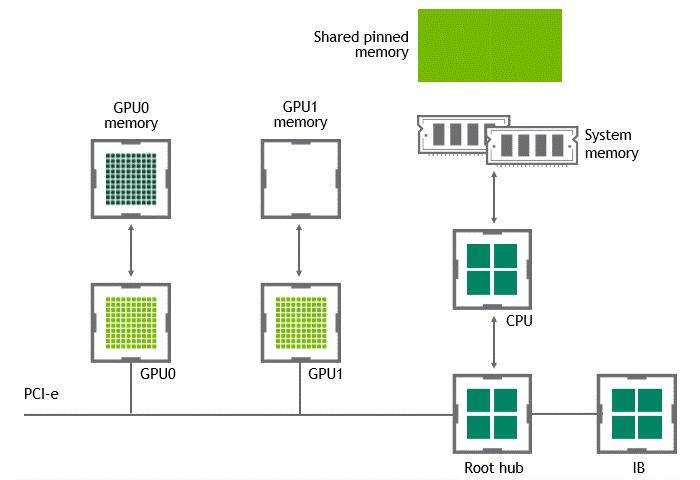
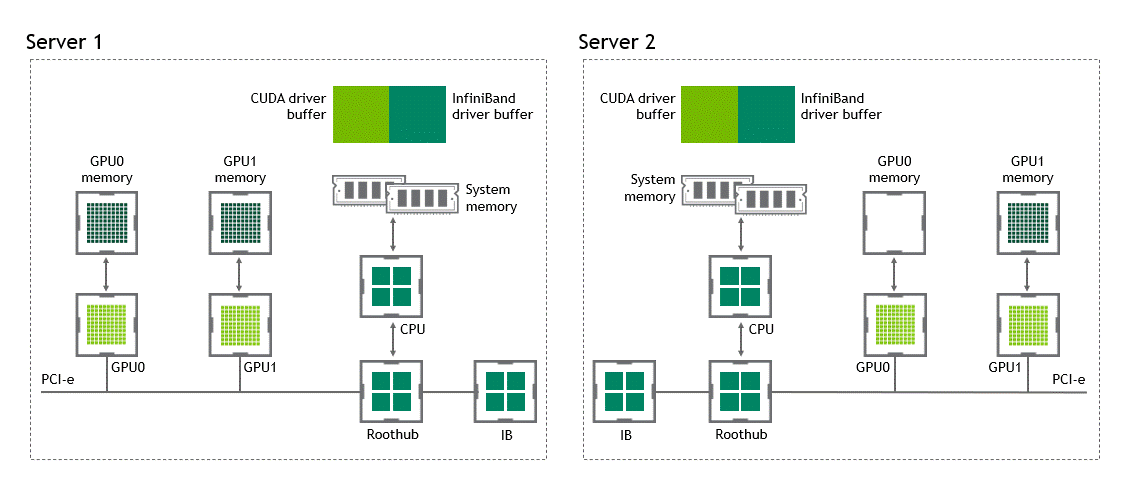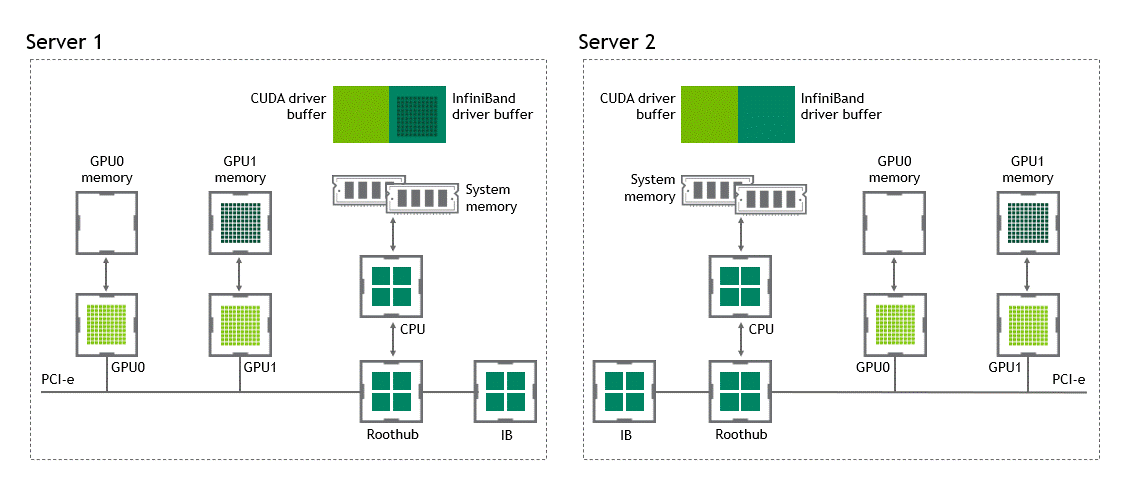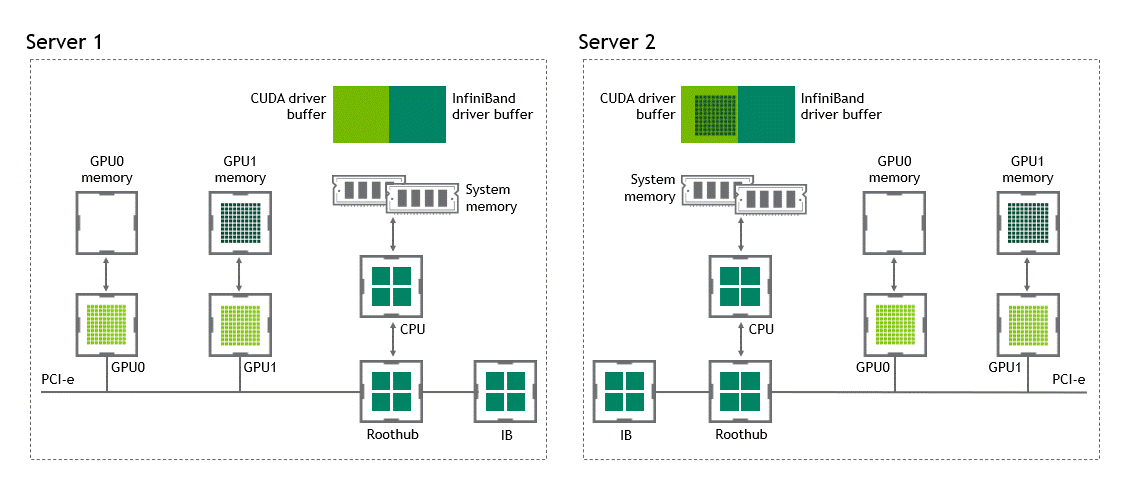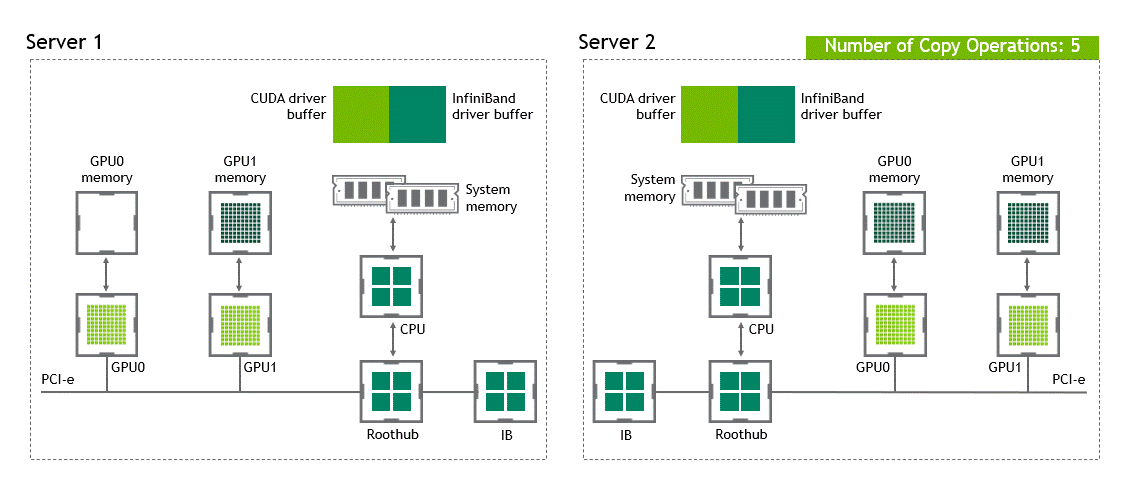
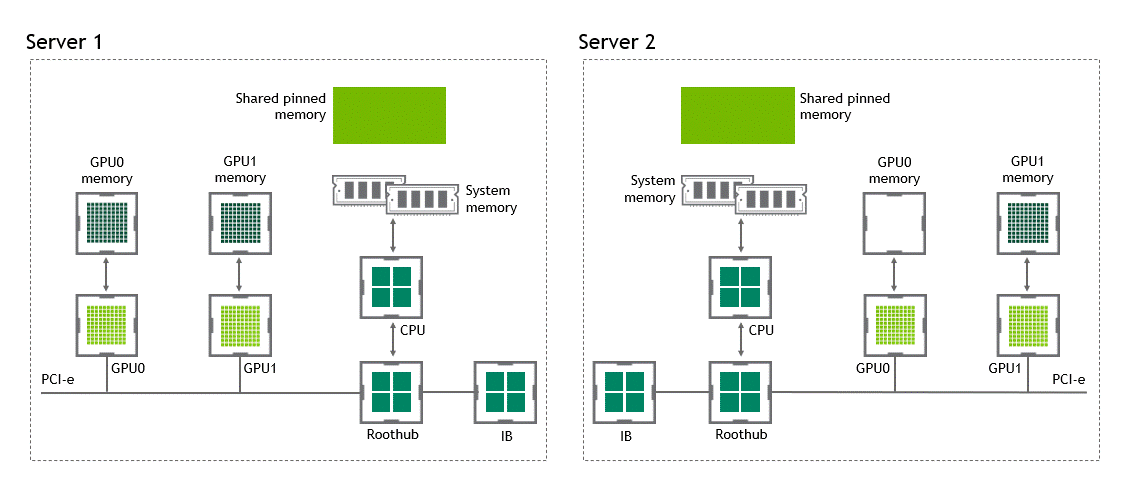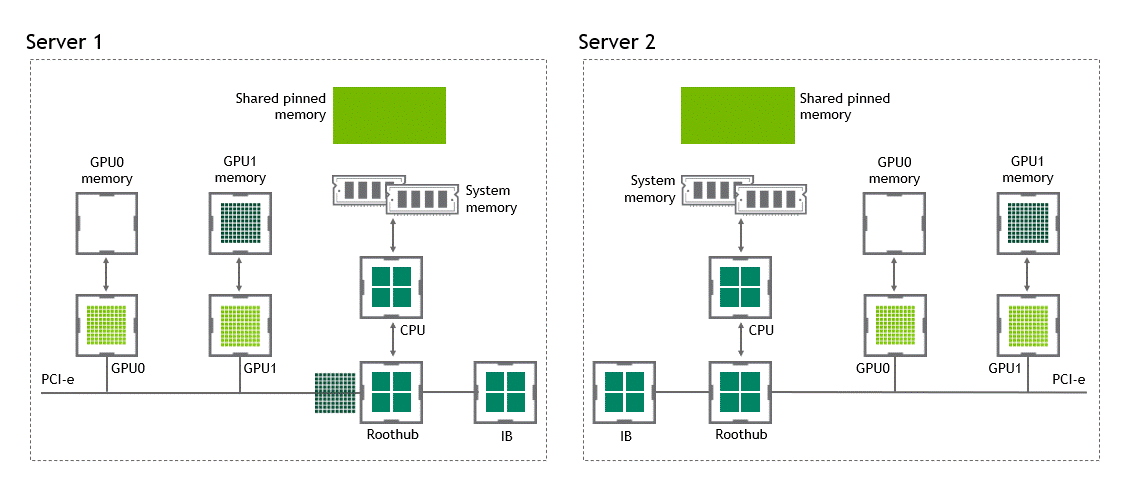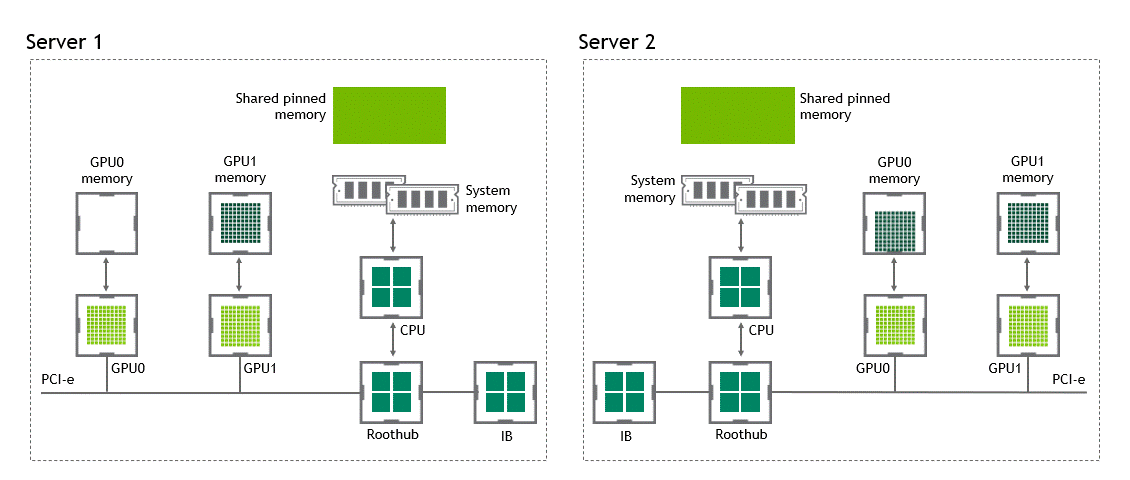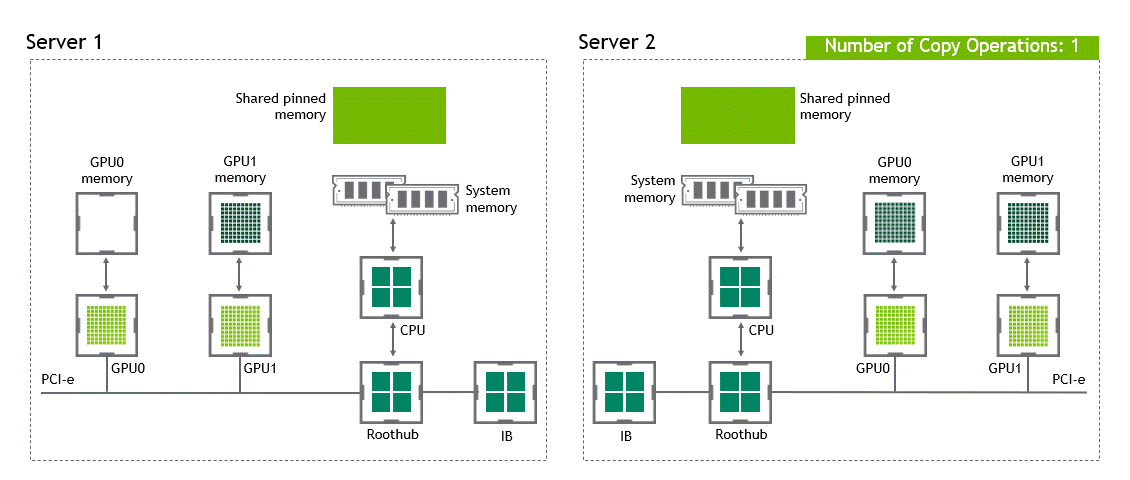
 Introduction Efficient pipeline design is crucial for data scientists. When composing complex end-to-end workflows, you may choose from a wide variety of building blocks, each of them specialized for a dedicated task. Unfortunately, repeatedly converting between data formats is an error-prone and performance-degrading endeavor. Let’s change that! In this post series, we discuss different aspects …
Introduction Efficient pipeline design is crucial for data scientists. When composing complex end-to-end workflows, you may choose from a wide variety of building blocks, each of them specialized for a dedicated task. Unfortunately, repeatedly converting between data formats is an error-prone and performance-degrading endeavor. Let’s change that! In this post series, we discuss different aspects …