
 Virtualization is key to making networks flexible and data processing faster, better, and highly adaptive with network infrastructure from Core to RAN. You can achieve flexibility in deploying 5G services on commercial off-the-shelf (COTS) systems. However, 5G networks bring support for ultra-low latency, high-bandwidth applications, and scalable networks with network slicing and software defined networking … Continued
Virtualization is key to making networks flexible and data processing faster, better, and highly adaptive with network infrastructure from Core to RAN. You can achieve flexibility in deploying 5G services on commercial off-the-shelf (COTS) systems. However, 5G networks bring support for ultra-low latency, high-bandwidth applications, and scalable networks with network slicing and software defined networking … Continued
Virtualization is key to making networks flexible and data processing faster, better, and highly adaptive with network infrastructure from Core to RAN. You can achieve flexibility in deploying 5G services on commercial off-the-shelf (COTS) systems.
However, 5G networks bring support for ultra-low latency, high-bandwidth applications, and scalable networks with network slicing and software defined networking (SDN). 5G networks, especially virtualized RAN (vRAN), require both performance based on fast data processing and flexibility by virtualization at the same time.
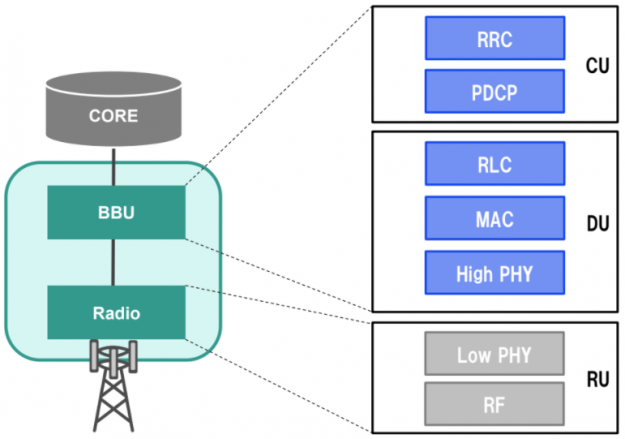
The bottleneck of vRAN is the data processing in the PHY layer. Figure 2 shows the functional block diagram with the Option 7.2x architectural split. The PHY layer converts bits to radio waves in downlink by using various algorithms for scrambling, channel encoding, equalization, rate matching, and the reverse for uplink flow. Fronthaul interfaces with external radio units using the eCPRI protocol to reduce latency and jitter during data transfer.
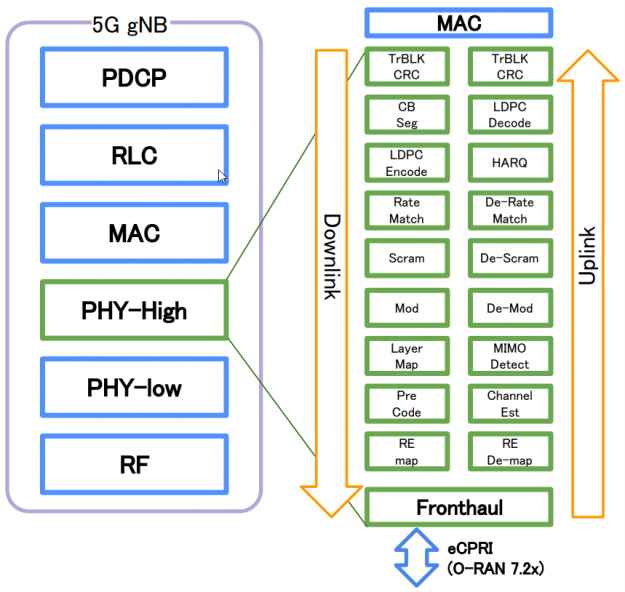
GPU-based vRAN processing handles massive computations and heavy workloads without compromising on speed. The NVIDIA Aerial SDK is a cloud-native 5G vRAN solution running on NVIDIA GPUs to bring high performance computing (HPC) and signal processing all in one package.
Motivation for the benchmark of GPU-based vRAN
In addition to high speed and high-capacity communications, 5G technology is expected to offer low-latency transmission, offering more advanced signal processing. Because previous vRAN designs fail to deliver the communication performance anticipated for 5G, validation tests are being carried out with a view to boosting processing speed. SoftBank, along with NVIDIA, has been conducting such validation tests since 2019.
The NVIDIA Aerial SDK conforms to the standard specified by 3GPP and O-RAN Alliance, making this software highly compatible with the generalization and virtualization of 5G base stations. With in-line acceleration and software defined implementation, the performance improves with advances in GPUs while no design changes are required. Massive MIMO type communication being an integral part of RAN, NVIDIA Aerial can support higher bandwidths and data rates without sacrificing flexibility from virtualization.
To be precise, GPU performance is determined by its clock frequency and number of cores. These are virtualized by the CUDA C/C++ platform. The hardware structure is well hidden, and automatically schedules multiprocess operations to run with sufficient parallelism. If the Aerial SDK runs on different GPUs (GPUs with different numbers of cores), there is no need for additional development due to hardware changes. The advantages of the CUDA platform enable you to run the existing code on those GPUs without modification.
Softbank was interested in the flexibility of this GPU-based vRAN and collaborated with NVIDIA to conduct this validation to investigate the performance and features.
Performance testing conditions
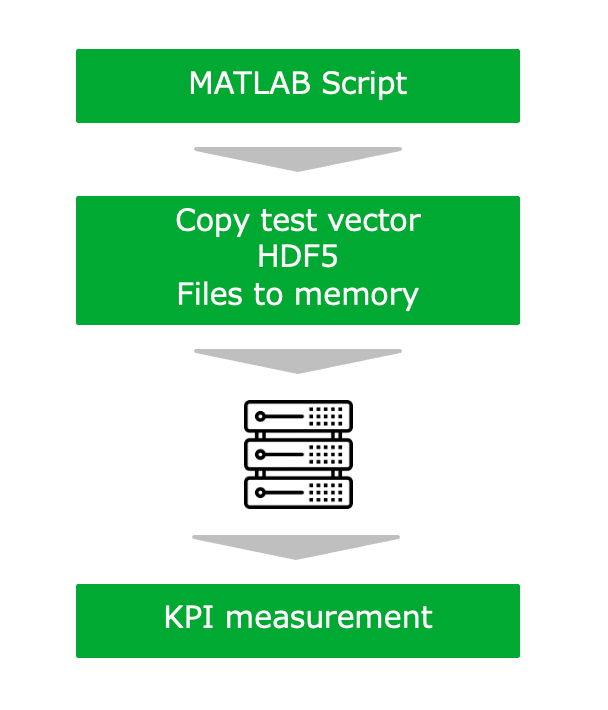
In this test, signal processing was conducted to simulate uplink and downlink data communication for latency and power consumption. The benchmark was run on the server equipped with an NVIDIA V100 GPU (Figure 3).
| Chipset | Intel Xeon CPU Platinum 8258(24 core 2.9GHz) |
| Accelerator | 100 MHz |
| Bandwidth | 100 MHz |
| #MIMI layers | UL: 1-8 Layers DL: 1-16 |
| Modulation | UL: 64 QAM DL: 256 QAM |
Tables 2 and 3 show the configuration details of the uplink and downlink test vectors.
| Bandwidth (MHz) | 100 | 100 | 100 | 100 |
| Cells | 1 | 2 | 4 | 8 |
| Total Layers | 1 | 2 | 4 | 8 |
| Total Users | 1 | 1 | 2 | 8 |
| Layers per user | 1 | 2 | 2 | 2 |
| Max length | 1 | 1 | 2 | 2 |
| QAM | 64 | 64 | 64 | 64 |
| Target code rate (R x 1024) | 948 | 948 | 948 | 948 |
| Downlink Test Case 1 |
Downlink Test Case 2 |
Downlink Test Case 3 |
Donlink Test Case 4 |
|
| Bandwidth (MHz) | 100 | 100 | 100 | 100 |
| Cells | 1 | 1 | 1 | 1 |
| Total layers | 2 | 4 | 8 | 16 |
| Total users | 2 | 4 | 4 | 4 |
| Layers per user | 1 | 1 | 2 | 4 |
| max length | 1 | 1 | 2 | 2 |
| QAM | 256 | 256 | 256 | 256 |
| Target code rate (R x 1024) | 948 | 948 | 948 | 948 |
Results
The benchmark resulted in significant advantages in signal processing time and power consumption.
100MHz signal processing time
Figure 4 shows that GPU-based vRAN (NVIDIA Aerial) showed a remarkable advantage in processing time. The x-axis shows the total number of layers, and the y-axis shows the signal processing time. As the number of layers increases, the complexity of the signal processing increases. However, the increase in GPU latency for PHY processing is not proportional to the actual processing time required, making it more efficient for a higher number of layers.
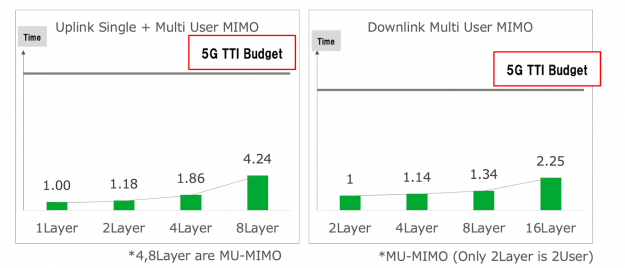
This testing was limited to a single cell. Multicell performance on GPU parallel processors cannot be estimated from single cell performance, as the results would greatly underestimate the gains from processing additional cells in parallel.
For example, in the case of uplink, when the number of processed layers is increased from one layer to two layers, the processing time increases by only 1.18 times. SoftBank concluded that this is because the processing is performed efficiently by the massive parallel computing ability of the NVIDIA GPU. They also observed that the GPU can easily meet the 5G TTI budget with a single cell, so performant multicell processing would be within scope.
Power consumption
In Figure 5, the green bars represent the average power consumption of GPU card, and an error bar shows the range of GPU power consumption (representation from minimum power consumption to maximum power consumption). The x-axis shows the total number of layers (uplink) in the same way we showed the signal processing graph in the previous section. The y-axis shows the power consumption.
As explained earlier, as the number of layers increases, PHY processing becomes more computationally intensive, which puts more strain on the GPU. However, focusing on the average power consumption represented by the green bar, the increase in GPU power consumption is gradual, despite the increasing GPU load. It increases 1.41 times from one layer to two layers, and 1.56 times from one layer to four layers.
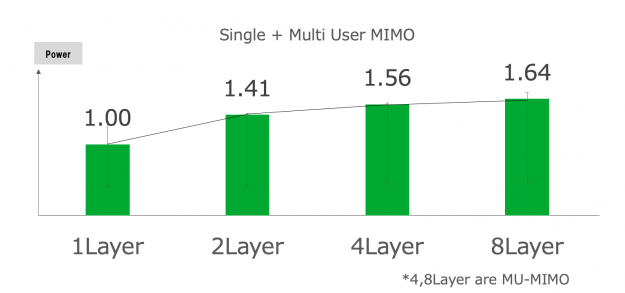
As the previously mentioned experiment showed, the power consumption of GPU-based vRAN demonstrated two important results:
- A rise in power consumption is not in proportion to the increase in the number of layers. This is going to be an advantage in case SoftBank deploys vRAN with a higher number of MIMO-layer configurations.
- Power consumption increased only when the GPU ran particular PHY signal processings. In other words, there is an evident correlation between GPU usage and the power consumption. This signifies that operators could cut down on the total power consumption if the vRAN system workload fluctuated a lot.
Importance of flexibility in deployment at edge
In 5G and beyond, we should expect the unexpected, especially when it comes to realizing new applications. In these potential applications, there will probably be some that require ultra-low latency to be meaningful, such as online gaming, AR/VR, and other typical MEC applications. You may not be able to put dedicated servers for these applications at edge, due to unavoidable limitations in terms of space, power draw, and other economic or engineering factors.
To tackle this type of adverse scenario, consider hosting latency-sensitive applications previously mentioned on a RAN system alongside 5GC functions necessary. This is the so-called “coexistence of 5G RAN and MEC” deployment scenario at which worldwide operators are aiming.

Because SoftBank is interested in the coexistence of 5G RAN and MEC, they are continuously verifying some applications using GPUs on MEC in parallel with this vRAN verification. For deployment scenarios that share resources at edge locations, they believe that there are some key requirements that cannot be ignored such as flexible programmability, cloud-native architecture, and proper multitenancy.
Through this vRAN validation, we confirmed the flexibility and high computational performance. Together with the fact that GPUs have a high affinity for AI processing, they felt that GPUs have an affinity for the coexistence of 5GRAN and MEC.
Because we both share the same views in the must-have edge requirements and ideal platforms in the future, SoftBank and NVIDIA are continuing to pursue this scenario in continuation of the successful vRAN benchmark.
Conclusion
Based on the key findings mentioned in this post, here are the conclusions SoftBank made in their GTC talk:
- RAN virtualization won’t stop. vRAN enables the adoption of open hardware with a software-defined RAN running on it, alongside other mobile capabilities such as MEC. These functional blocks are interconnected using open standard interfaces.
- Choose the right accelerator. To cope with computationally intensive PHY signal processing in open hardware platforms, you must choose the right accelerator. There are a couple of choices currently available on the market, GPU and others. The important factors to keep in mind are the hardware platform’s versatility, computing performance, cost, and its inherent programmability.
- GPUs are an ideal commercial vRAN solution in 5G networks. GPUs have valuable benefits, such as edge hardware resource sharing (MEC applications to be hosted on the same converged platform as gNB along with part of 5GC components) and its intrinsic programmability powered by CUDA.
- GPUs consume power proportionally. From time to time, the traffic to be processed by a gNB can be low. The way that GPUs consume power proportionally is beneficial in such cases, unlike other accelerators.
For more information, see the following resources:
- NVIDIA Aerial SDK
- [TITLE], SoftBank GTC webinar (Japanese/English)
 In XGBoost 1.0, we introduced a new, official Dask interface to support efficient distributed training. Fast-forwarding to XGBoost 1.4, the interface is now feature-complete. If you are new to the XGBoost Dask interface, look at the first post for a gentle introduction. In this post, we look at simple code examples, showing how to maximize …
In XGBoost 1.0, we introduced a new, official Dask interface to support efficient distributed training. Fast-forwarding to XGBoost 1.4, the interface is now feature-complete. If you are new to the XGBoost Dask interface, look at the first post for a gentle introduction. In this post, we look at simple code examples, showing how to maximize … 
 Researchers from University of Washington and Facebook used deep learning to convert still images into realistic animated looping videos. Their approach, which will be presented at the upcoming Conference on Computer Vision and Pattern Recognition (CVPR), imitates continuous fluid motion — such as flowing water, smoke and clouds — to turn still images into short …
Researchers from University of Washington and Facebook used deep learning to convert still images into realistic animated looping videos. Their approach, which will be presented at the upcoming Conference on Computer Vision and Pattern Recognition (CVPR), imitates continuous fluid motion — such as flowing water, smoke and clouds — to turn still images into short … 